본 글에서는 Recsys2022에서 확인할 수 있었던 흥미로운 논문들 중 일부를 리뷰하고 정리해보도록 하겠습니다.
Papers
Two-layer Bandit Optimization for Recommendations (Apple)
app marketplace에서 수 많은 앱 목록을 개인화된 알고리즘을 통해 노출시킨다고 하면 여러 어려움에 직면할 수 있습니다. item(앱) 종류가 매우 다양하고 시시각각으로 변한다는 것 외에도 cannibalization이 발생할 수 있습니다. 예를 들어 특정 앱을 우선적으로 추천한다고 할 때 어쩌면 어떤 user는 그 item을 다운로드 받은 후 더 이상 필요한 앱을 찾아보지 않고 marketplace를 떠나버릴지도 모릅니다.
apple에서는 이러한 문제를 해결하기 위해 굉장히 이해하기 쉬우면서도 효과적인 추천 시스템을 설계했습니다. 그들의 목표는 전체적인 engagement를 저해하지 않으면서도 추천한(Suggested) item의 engagement를 증가시키는 것이었습니다.
논문에서는 Two-layer Bandit 구조가 제안되었습니다. 아래와 크게 Bandit Recall Layer와 Bandit Ranking Layer로 구성됩니다.
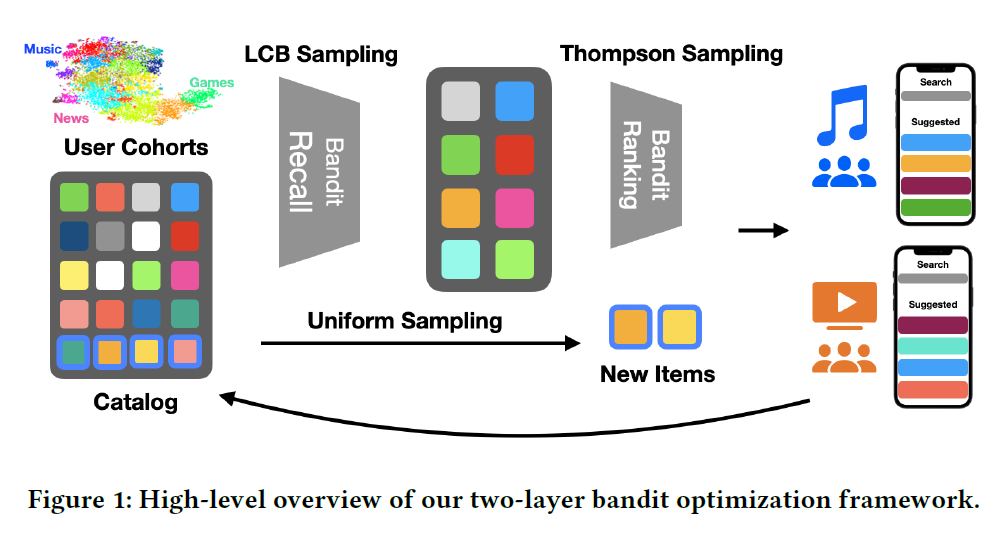
전자는 candidate들을 선정하고, 후자는 최종 랭킹을 결정하게 됩니다. update를 위해 cohort-level effective rewards 데이터가 수집됩니다. cohort-level로 reward를 계산한다는 부분이 색다르게 느껴집니다. user-level이 아니라 cohort-level로 reward를 계산하게 되면 어쩌면 완벽한 초개인화를 달성하는 것은 힘들 수 있다 하더라도 실제 시스템을 운영할 때의 효율은 훨씬 향상될 수도 있을 것입니다. 유사한 취향을 가진 고객들을 K-Means 알고리즘을 통해 grouping하고 이를 바탕으로 cohort를 구성합니다.
논문에서는 effective rewards를 아래와 같이 정의하였습니다.
\[F_{\text CC}(i, C_j) = {\text max} (S^i_{C_j} - D^i_{C_j}, 1)\]여기서 $i$ 는 item index를 의미하고, $C_j$ 는 $j$ 번째 cohort를 의미합니다. $S$ 는 검색을 한 번이라고 하고 item을 다운로드 받은 적이 있는 user session의 수를 의미하고 $D$ 는 검색 없이 다운로드 한 user session의 수를 의미합니다. 즉 이러한 reward 설계는 cannibalization을 방지하겠다는 의도를 담고 있습니다.
만약에 cannibalization을 고려할 필요가 없다고 한다면 $S$ 만 고려해도 될 것입니다. 혹은 다운로드 수 뿐만 아니라 좀 더 다양한 요소를 반영하고 싶다면 reward 식을 더 복잡하게 개량할 수도 있을 것입니다.
Bandit Recall Layer의 핵심은 각 cohort에게 너무 어울리지 않을 법한 item을 빼고 추천 후보 리스트를 만드는 것입니다. 이 때의 기준은 conversion rate이 됩니다.
각 cohort-item pair에 대하여 로그 데이터를 활용하여 모든 empirical conversion rate을 구해줍니다. 그리고 conversion rate이 이항 분포를 통해 형성되었다고 가정하고 CLT를 활용하여 정규분포 형태로 바꿔줍니다. 그리고 여기서 각 cohort-item pair에 대해 95% LCB: Lower Confidence Bound를 계산하고 특정 임계값을 넘는 pair만 남겨둡니다. 그리고 각 cohort에 대해 후보 item들의 선택받을 확률을 softmax 함수를 통해 구성해주면 됩니다. 논문에서는 수백 개 정도의 item을 남겨두었다고 기술하고 있습니다.
보통 UCB: Upper Confidence Bound를 적용하는 사례를 많이 보게 되는데, 이 논문에서는 LCB: Lower Confidence Bound를 적용하였습니다. 왜냐하면 이 단계는 최종 단계가 아닌 item 후보 목록을 선정하는 단계이기 때문에 가장 relevant한 item을 찾는 것보다 irrelvant한 item을 걸러내는 것이 더 중요한 작업이기 때문입니다. (상대적으로 더 보수적인 접근 방법입니다.)
LCB Sampling 과정이 끝나면 Thompson Sampling 전략이 적용된 Bandit Ranking Layer가 이어집니다. 샘플링은 다음과 같은 분포에 의거하여 이루어집니다.
위 과정을 통해 relevant한 item을 선별하고 추가적으로 uniform sampling을 통해 cold item이 소외받지 않도록 해줍니다. 이를 통해 모델의 confirmation bias를 줄일 수 있습니다. 계속 같은 item을 보여줄 수는 없으니까요.
실험의 결과는 물론 단순 uniform sampling 보다 위와 같은 Two-layer Bandit 구조가 우수하다는 것을 증명합니다. 그런데 흥미로운 부분은, LCB와 달리 Thompson Sampling만을 적용했을 때 Cannibalization 현상이 발생했다는 점입니다.
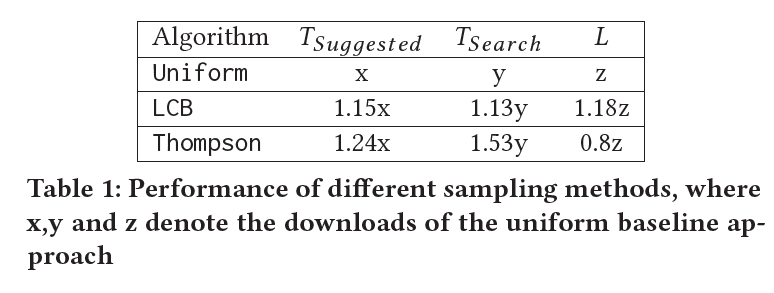
만약 Thompson Sampling만을 이용했다면 비록 relevance는 올라갔을 수 있지만 실제로 서비스에서 추구하는 결과와는 좀 멀어졌을 수도 있겠다는 생각이 드는 대목이었습니다. LCB sampling와 uniform sampling을 함께 적용함으로써 균형적인 결과를 얻을 수 있었던 것으로 보입니다.
Extending Open Bandit Pipeline to Simulate Industry Challenges (Booking.com)
이 논문은 새로운 알고리즘을 소개하는 논문이 아닙니다. 실제 현실에서 Bandit Optimization 문제를 풀기 위해서 맞닥드리는 여러 상황과 의문점을 제시하고 이를 실험을 통해 더욱 쉽게 접근할 수 있도록 오픈 소스 라이브러리를 확장했다는 이야기를 담고 있습니다.
OBP: Open Bandint Pipeline은 off-policy learning & evaluation 을 위한 라이브러리입니다. 논문 또한 존재합니다.
논문에서는 크게 5가지의 주요 문제를 언급합니다.
- on-policy, off-policy 둘 중 어떤 알고리즘을 선택할 것인가?
- delayed reward는 어떻게 다룰 것인가?
- 다양한 유형의 drift는 어떻게 다룰 것인가? (빠르게 environment가 변화하는 현상)
- relastic reward는 어떻게 정의하는가?
- 수많은 비즈니스 규칙과 끈임없이 변화하는 arm 속에서 어떻게 bandit 문제를 최적화할 것인가?
정말 머리 아픈 문제들이 틀림 없습니다. 논문에서는 몇 가지 가이드를 제시하고는 있지만, 골자는 결국 실험을 통해 알아보는 것이 최선이라는 것입니다. OBP를 활용하면 좋겠네요.
On-policy vs Off-policy
일반적으로 bandit 알고리즘들은 On-policy로 최적화합니다. 즉 각 step(round) 마다 policy로 부터 action을 추출해서 explore/exploit 하게 됩니다. Off-policy는 반대로 policy를 기존에 존재하는 데이터로 부터 학습하고 그 후 production에 세우게 됩니다. 보통은 IPW: Inverse-propensity Weighting 을 이용하여 로그 데이터의 편향을 줄이는 방식으로 구현합니다.
On-policy는 실제 상황에서 적용하기에는 초기 비용이 크다는 단점이 있습니다. 충분한 exploration이 이루어지는 동안 실제 비즈니스 비용은 계속 지출될 것이니까요. 그리고 user experience를 해칠 수도 있습니다.
논문 부록에 첨부된 실험 결과를 한 번 보겠습니다.
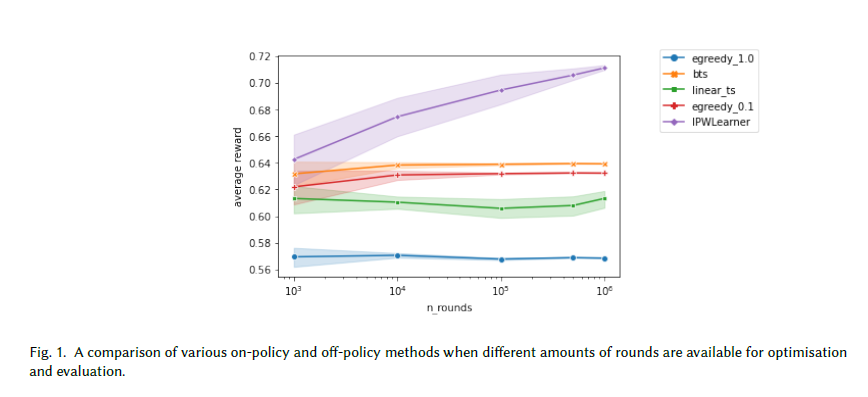
IPW를 활용하여 off-policy로 학습한 결과가 더욱 좋습니다. 이는 꼭 처음부터 On-policy를 고집할 이유는 없다는 것을 증명한 사례이기도 합니다. 직접 실험해보면 좋겠네요.
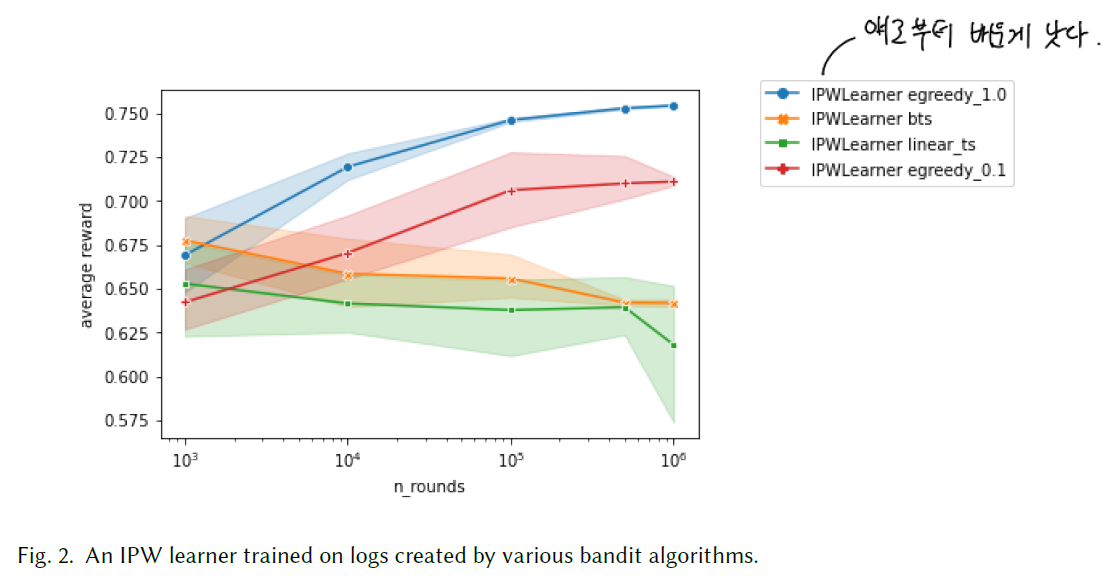
logging policy에 따른 성능 차이도 보여줍니다. 높은 exploration의 egreedy_1.0이 가장 우수한 결과를 이끌어 냅니다.
Concept Drift & Non-stationarity
Drift와 Non-stationarity 문제는 현실적으로 거의 무조건 마주칠 수 밖에 없는 문제입니다. 아마 drift 후에 얼마나 빠르게 on-policy 방법론은 회복할 수 있을지, 어떠한 종류의 drift가 가장 challenging할지, off-policy 방법론을 어떻게 non-stationary 환경에 적용할지 등의 문제를 마주하게 될 것입니다.
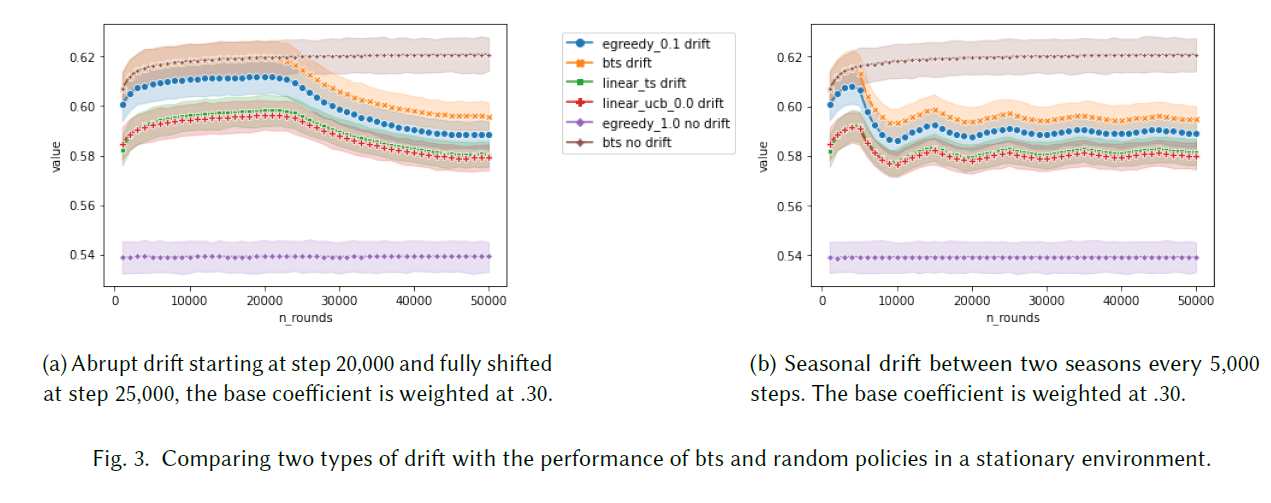
논문에서는 갑작스런 drift로 인한 성능저하와 seasonal drift로 인한 성능저하 및 회복 기간에 대한 인사이트를 제공합니다.
Delayed Reward
리워드가 지연되어 지급되는 경우는 굉장히 빈번합니다. 구매 확정이 며칠 뒤에 발생하는 것이 대표적인 예일 것입니다. 이러한 상황은 어떠한 영향을 끼칠지 시뮬레이션 해보는 것은 중요한 문제입니다.
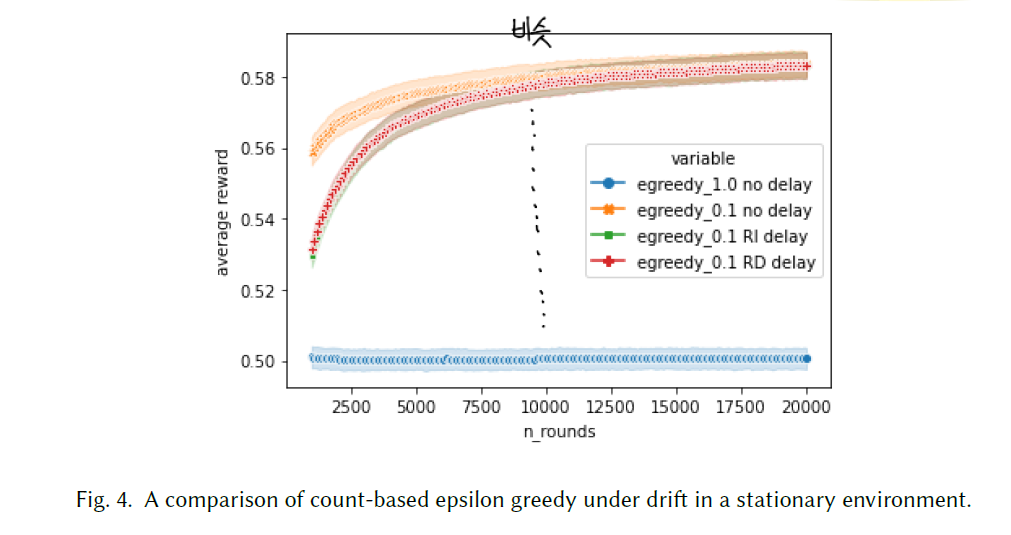
논문에서의 실험을 보면, 초반에는 delayed reward로 인한 격차가 눈에 띄게 보이지만, 일정 시점 이후에는 거의 같아진다는 것을 보여줍니다. 실제 적용 상황을 생각해본다면, off-policy 학습을 통해 어느 정도의 step 수가 필요한지 가늠해 볼 수도 있을 것입니다.
Reward Design and Multi-Reward
business objective와 reward가 정확히 일치하는 것은 상당히 이상적인 시나리오에서나 가능합니다. 보통은 sparsity, delay나 여러 복잡한 상황들로 인해 괴리가 있는 것이 사실입니다. 논문에서는 sub-optimal 한 결과로 이어지지 않으면서도 어떻게 잘 최적화할 수 있을지에 대한 질문을 던집니다.
Business Rules and Arm Availability
policy가 action을 선택해도 여러 비즈니스 규칙과 상황으로 인해 그 action이 실제로 추천 리스트에 없을 수도 있습니다. 이렇게 되면 policy의 exploration 능력은 제한될 수 밖에 없습니다. 추가적으로 로그 데이터의 편향을 제거하는 것은 굉장히 어려운 일이 됩니다. 관련해서 이러한 문제를 다룬 연구들이 있습니다. 논문 본문을 참고하면 좋을 것 같네요.
EXTENSIONS TO OPEN BANDIT PIPELINE
앞서 설명했던 여러 문제를 해결하기 위해서는 쉽게 실험을 해볼 수 있어야 합니다. 논문에서는 아래 class 개발을 통해 좀 더 쉽게 테스트를 진행할 수 있도록 기여했다고 기술하고 있습니다.
- BanditEnvironmentSimulator and BanditPolicySimulator
- CoefficientDrifter
- ExponentialDelaySampler
On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models (Google)
구글의 검색 광고 CTR 모델에 실질적으로 적용된 기술에 대해 살펴본 논문입니다.
먼저 ML Efficiency 측면에서 살펴보겠습니다. 정확도를 높이는 것은 매우 중요한 일이긴 합니다. 그러나 실제 현실에서는 training & inference cost를 고려하지 않을 수 없습니다. 즉 이 둘 사이의 균형을 적절히 유지하는 것이 효율적인 ML 시스템 설계의 핵심이 될 것입니다.
이 때 cost를 결정하는 주요 요인으로는 bandwidth(학습시켜야 하는 모델의 수), latency(새로운 모델을 위한 end-to-end 평가 시간) 그리고 throughput(단위 시간 내에 학습 가능한 모델) 이 있겠습니다.
효율을 높이면서 균형을 유지하기 위한 방법에는 여러가지가 있지만 본 논문에서는 대표적으로 3가지 측면에서 이 주제를 다루고 있습니다.
- Bottlenecks
정확도를 높이다 보면 모델의 크기가 커지고 layer를 구성하는 벡터의 차원 수가 커지기 마련입니다. 그런데 이 때 발생하는 수 많은 행렬 연산들은 속도 하락의 주범이 되기도 합니다. 이 때 SVD와 같은 테크닉을 이용한다면 정확도 손실은 최소화하면서 어느 수준까지 training cost를 감소시킬 수 있을지도 모릅니다.
- AutoML for efficiency
실제 필드에서 주구장창 hyper-parameter tuning을 하고 있기란 쉽지 않습니다. 이를 피하기 위해서는 효율적인 NAS(Neural Architecture Search) 시스템이 필요합니다. 본 논문에서는 weight-sharing network, RL controller 그리고 constraints 라는 3가지 구성을 통해 효율적인 ML 알고리즘을 구성하는 방법에 대해 설명합니다.
- Data Sampling
어쩌면 가장 powerful한 조작이 아닐까 하는 생각이 드는 부분입니다. raw 데이터는 noisy하고 중복된 역할을 하는 데이터도 넘쳐납니다. 본 논문에서는 class re-balancing과 loss-based sampling 기법을 통해 학습 데이터의 양을 1/4로 줄인 사례를 통해 training cost를 줄인 방법에 대해 설명합니다.
Accuracy 자체를 늘리는 방법에는 무엇이 있을까요? 본 논문에서는 Loss 함수를 적절히 변형하거나 2nd-order optimization을 이용하거나 deep & cross network를 이용하여 이를 달성하는 사례에 대해 자세히 소개하고 있습니다.
이 외에도 논문에서는 실제로 ML 시스템을 구성할 때 고려해야 하는 여러 사항에 대해 서술하고 있고, 좀 더 효율적인 시스템을 설계하는 데에 도움이 될 만한 사항들을 기술하고 있습니다.
Effective and Efficient Training for Sequential Recommendation using Recency Sampling
실제 필드에서 모델을 학습시킬 때 가장 난감한 부분 중 하나는 학습 데이터를 구성하는 일입니다. 빠르게 학습이 진행되면서도 높은 수준의 정확도를 갖게 만드는 것은 이전 논문에서도 다루었던 것처럼 쉽지 않은 일이긴 합니다.
학습 속도가 느리다면 이는 실제 product를 만드는 과정을 느리게 할 뿐만 아니라 user preference가 변할 때 이를 빠르게 포착하지 못할 수도 있습니다.
본 논문에서는 next-item prediction을 목적으로 하는 sequential recommendation에서 효과적으로 학습 데이터셋을 구성해서 빠르고 높은 수준의 학습 커브를 만드는 방법에 대해 제안합니다. 실제 적용하기에도 아주 가치가 높은 참고자료가 될 것이라고 확신합니다.
대부분의 sequential model들은 학습이 느리다는 문제를 갖고 있습니다. 그리고 이들의 학습 과정을 보면 2가지 문제가 있는데, 일단 next-item prediction 과정에서 sequence의 시작은 학습 데이터로 사용하지 않는다는 점입니다. 이 데이터 또한 분명 가치가 있는 데이터일 텐데 구조의 효율을 높이기 위해 이 부분을 사용하지 않는다는 것은 분명 데이터의 손실을 의미합니다. (개인적으로는 이 부분이 아주 큰 영향을 미치지는 않을 것 같다는 생각은 갖고 있습니다.)
두 번째로 보통 sequence 내에서 무작위로 item을 masking하고 이들에 대한 예측을 수행하는 것을 model의 학습 task로 설정하는데, 사실 이러한 task가 sequential recommendation의 완전한 end goal이라고 보기는 어렵습니다. 왜냐하면 결국 우리는 next-item을 예측해야 하지 중간에 있는 item을 예측할 일은 드물 것이기 때문입니다. 이 때문에 training sample과 evaluation sample의 분포는 다를 수 밖에 없습니다.
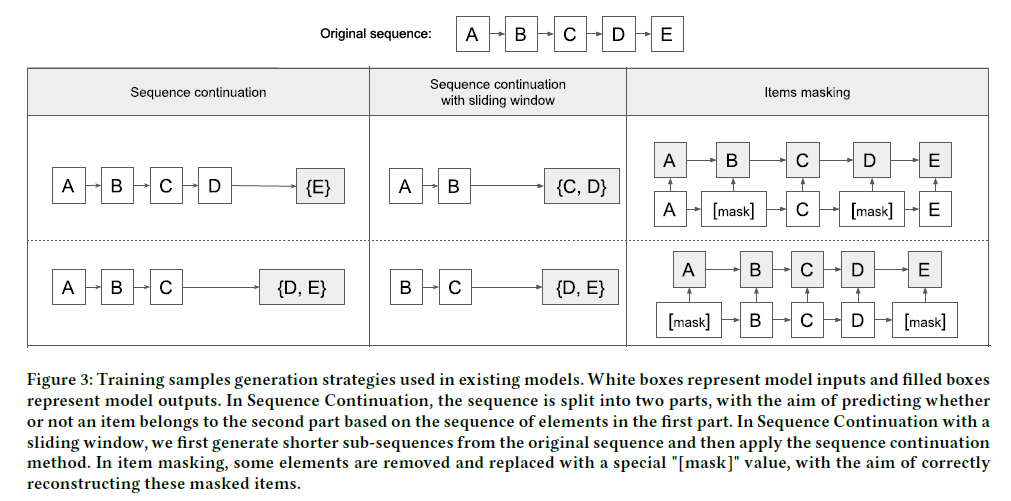
본 논문에서는 이러한 측면들을 고려하여 RSS (Recency-based Sampling of Sequences)를 제안합니다. 우리가 sequential 추천 모델에서 자주 고려하게 되는 SASRec, Bert4Rec 등에서도 결합해서 사용할 수 있기 때문에 사용성 측면에서 우수하다고 이야기할 수 있습니다. 참고로 본 논문에서는 random sampling, in-batch negative sampling 및 negative sampling with highest score와 같은 negative sampling 기법은 다루지 않습니다. 같이 적용해서 실험해 보는 것도 좋은 아이디어가 될 것입니다.
RSS의 개념은 아래와 같이 정리할 수 있습니다.
- 하나의 sequence에서 target을 추출하는데, 복수의 item이 target으로 추출될 수 있음
- 최근 item이 target으로 뽑힐 확률이 더 높음
위 확률은 recency importance 함수에 의해 결정되는데, 간단히 생각해서 단조 증가하는 함수면 됩니다. 논문에서는 아래와 같은 지수 함수 형태를 사용했습니다.
\[f(k) = \alpha^{n -k }\]이 때 $n$ 은 sequence의 길이를, $k$ 는 해당 item의 position을 의미합니다. 몇 개의 item을 target으로 설정할지는 hyper-parameter로서 조정하면 됩니다. 위 함수에서 $\alpha$ 가 0에 가깝게 된다면 최근 item이 뽑힐 확률이 더욱 높아지게 되고 반대로 1에 가깝게 된다면 각 item의 추출 확률은 비슷하게 구성될 것입니다.

위 그림에서 보실 수 있듯이, 모든 sample은 target이 될 가능성을 갖고 있습니다. 다만 그 확률이 조금씩 다를 뿐입니다. $\alpha$ 는 0.8 정도로 보통 세팅되는데, 경우에 따라 0.2 ~ 0.9 사이의 값을 설정할 수 있다고 논문에서는 기술하고 있습니다. 결국은 target으로 지정된 item은 그 training sample 상에서는 가장 마지막에 위치한 next-item으로 선정되는 것입니다.
이는 언뜻 보면 기존 sequence의 순서를 변경했기 때문에 무언가 잘못을 한 것은 아닌가 하는 생각도 들지만, 사실 어떤 물건을 구매하거나 어떤 컨텐츠를 클릭/소비한다고 했을 때 이 모든 것이 엄격하게 순서에 맞게 배치되는 경우는 그리 많지 않을 수 있습니다. $\alpha$ 라는 hyper-parameter에 의해 최근 item이 target으로 선정되는 경우가 더 많을 수 밖에 없기 때문에 sampling의 특성을 고려해보면 충분히 합리적인 데이터셋이 구성될 수 있다는 생각을 하게 됩니다.

논문에 등장한 비교대상 중 하나인 GRU4Rec을 제외하고는 BCE Loss를 통해 학습이 진행됩니다.
실험 결과를 자세히 살펴보는 것을 추천합니다. 총 4개의 데이터셋이 사용되었지만 Booking.com 데이터셋은 그 특성 때문에 결론을 낼 때 자주 제외됩니다. GRU4Rec, Caser, SASRec, Bert4Rec이 실험 대상 알고리즘으로 등장합니다. 그리고 SASRec의 원 논문에서는 학습할 때 모든 position에 대해서 output을 출력하고 이를 통해 학습이 진행되는데, RSS를 적용하기 위해서는 마지막 output만 필요하기 때문에 2가지 세팅을 모두 적용해서 2개의 모델 버전을 준비해서 실험이 진행되었다고 합니다. 그리고 Bert4Rec을 제외하고는 item masking은 적용되지 않았습니다.
실험 결과는 아래와 같습니다.
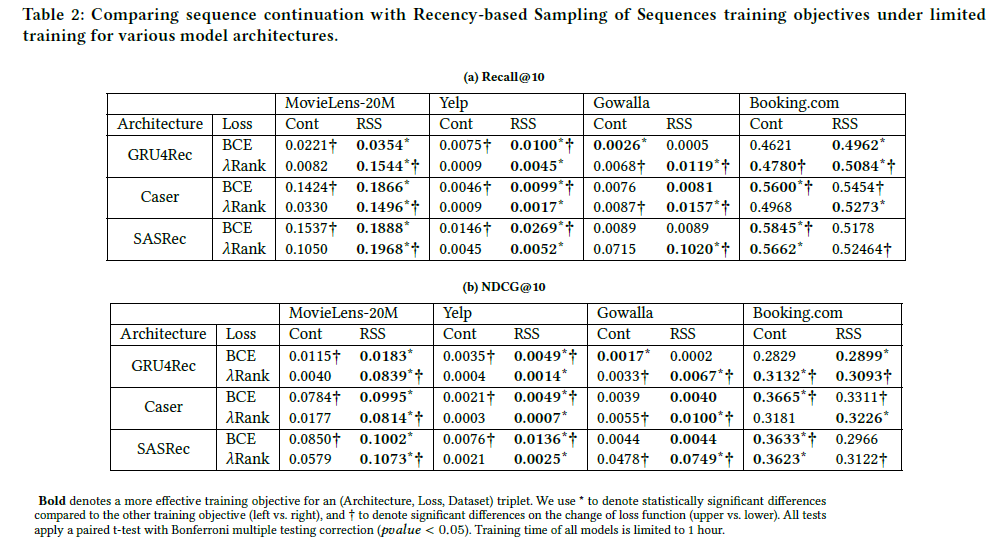
Table2를 보면 전체적으로 RSS를 적용했을 때 더 좋은 성능을 보인다는 것을 알 수 있습니다.
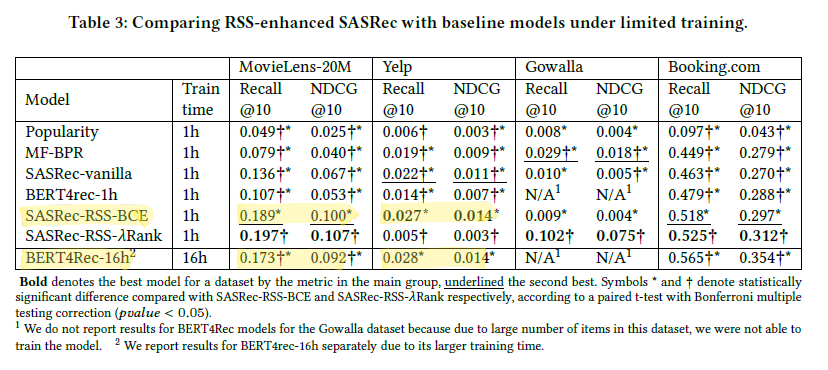
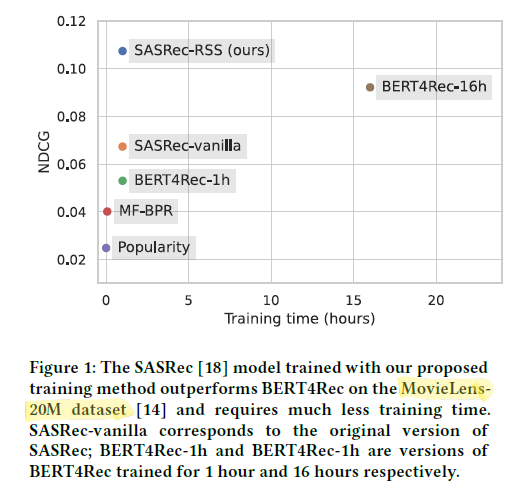
Table3에 가장 중요한 비교 결과가 기록되어 있습니다. SASRec-RSS-BCE는 학습 시간이 1시간에 불과하지만 16시간을 투자한 Bert4Rec-16h에 비해 MovieLens-20M 데이터셋에서 더 높은 성능을 보였습니다. 이 부분이 논문에서 가장 강조되어 있는 성능 향상 파트입니다. 전체 테이블의 기록을 보면 아시겠지만 모든 데이터셋에서 이러한 결과가 나오는 것은 아닙니다. 하지만 같은 학습 시간(1시간)을 주었을 때는 SASRec-RSS가 상대적으로 더 뛰어난 효율과 성능을 보이는 것은 꽤 합리적인 추론으로 보입니다.
정리를 해보자면, 본 논문은 sequential model을 학습할 때 item을 masking해서 학습 데이터셋을 구성하는 것보다 recency에 가중치를 둔 sampling 전략을 통해 학습 데이터셋을 구성하는 것이 충분히 더 효율적이고 우수한 성능을 보여줄 수 있다는 가능성을 증명하고 이에 대한 합리적인 근거를 제공했다고 볼 수 있겠습니다.
Personalizing Benefits Allocation Without Spending Money (Booking.com)
pdf 파일에는 소개만 적혀있습니다. 본 내용은 해당 링크의 Supplementary Material에 있는 영상 파일에서 확인하실 수 있습니다. 그리고 본 설명을 정확히 이해하기 위해서는 2년 전에 발표된 이 논문을 읽어보아야 합니다. 영상 후반부에 나온 수식이 이곳에서 등장하기 때문입니다.
기업이 프로모션을 진행한다고 했을 때 무작정 공격적인 행보만을 보일 수는 없습니다. 예산에 제약이 있기 때문이죠. Booking.com 에서 이렇게 budget constraint 가 있을 때 Personalized Promotion Assignment를 어떻게 하면 효과적으로 할 수 있는지에 대해 발표했습니다.
이러한 분야를 Uplift Modeling이라고 부르는데, 한 개인에게 특정한 행동을 가하고 이에 대한 CATE, 즉 Conditional Average Treatment Effect를 추정하는 ML 기법입니다.
고객이 특정 상품을 구매하는 행동에 대해 할인 쿠폰을 발급할 수도 있고, 그렇지 않을 수도 있습니다. 고객은 결과적으로 그 상품을 구매할 수도 있고, 하지 않을 수도 있습니다. 그렇다면 총 4가지 경우가 생깁니다.
- 구매O, 할인O
- 구매O, 할인X
- 구매X, 할인X
- 구매X, 할인O
마지막 케이스는 드물긴 하겠지만 분명 발생할 수 있습니다. 만약 위와 같은 케이스들에 대한 데이터를 갖고 있다고 해봅시다. 여러 마케팅 시도들에 의해 축적된 데이터가 있을 것입니다.
그렇다면 이제 우리가 알아야 할 것은 바로 아래와 같이 CATE를 추정하는 일입니다. 이 라이브러리를 참고하면 도움이 될 것 같습니다.
위 Score를 모든 고객에 대해 구한 뒤 분포를 확인해보았을 때, 아래 그림 상에서 초록색 영역에 속한 고객들에 대해서만 promotion이 이루어져야 할 것입니다.
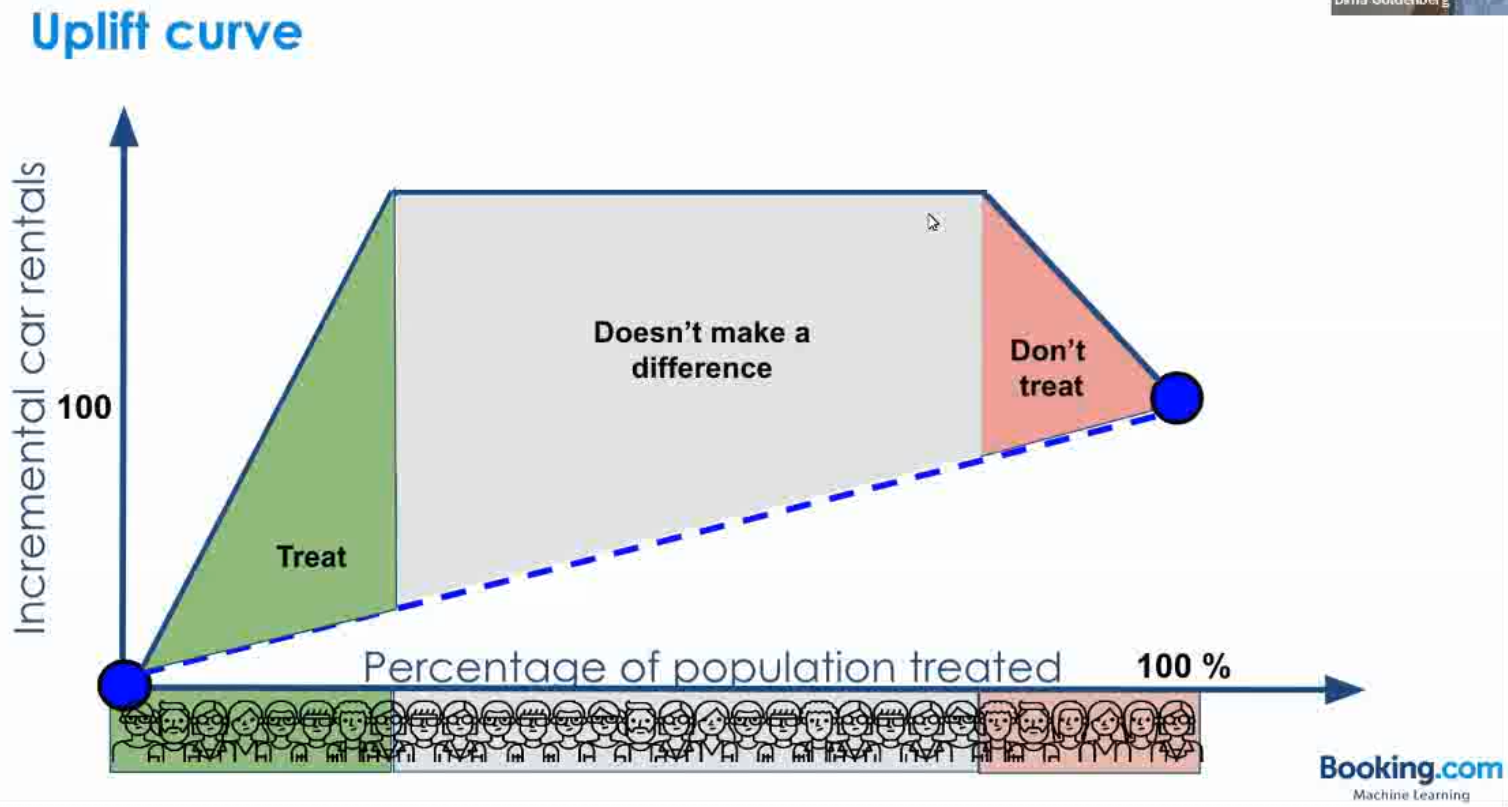
초록색 영역을 적절히 정할 때에는 결과적으로 예산의 크기가 중요한 요소로 작용하게 될 것입니다.
이 케이스는 Knapsack 문제라고 볼 수 있는데, 이 때 value와 weight은 아래와 같이 정의할 수 있습니다.
본 논문에서 소개한 기법과 이론적인 배경에 대해서는 이 글에 정리를 해두었습니다.
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach (Pinterest)
Pinterest에서 꾸준히 내고 있는 핵심 추천 시스템 관련 논문입니다. 본 논문에서도 등장하고 있는 PinSAGE, PinnerSAGE 그리고 PinnerFormer 까지 미리 읽고 보면 이해가 더욱 잘 될 것입니다.
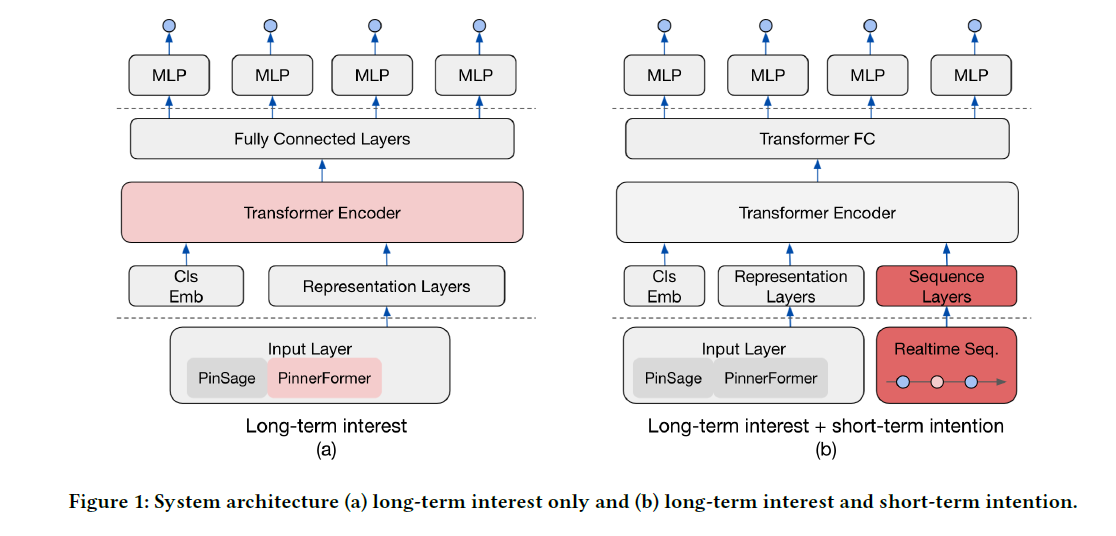
PinSAGE로 부터 pin(item)에 대한 embedding 벡터를 얻습니다. visual, text 그리고 Pixie를 통해 생성된 engagement information을 사용해서 학습됩니다.
User는 각 pin에 대해 클릭, 저장 및 상세보기를 할 수 있습니다. 이 action에 대한 type, timestamp, duration 그리고 surface 정보를 얻을 수 있습니다. 이 때 type과 surface 정보는 embedding table을 이용하여 인코딩됩니다. duration은 log(duration)의 형태로 표현됩니다. timestamp의 경우 좀 더 추가적인 과정을 거칩니다. 마지막 action 이후 지난 시간과 action 사이의 time gap이 새로 생성되며, 이들에 대한 인코딩은 P fixed period 하의 Time2Vec와 유사한 방식으로 수행됩니다.
pin embedding 벡터와 user의 action에 대한 meta feature를 모두 하나의 single vector로 이어 붙이면 1개의 action에 대한 input feature가 완성됩니다. 최근 $M$ 개의 sequence를 사용한다고 하면 각 user 당 (M, num_input_features) 형태의 input matrix를 얻게 됩니다.
PinnerFormer의 구조 자체는 특별하지는 않습니다. 기본적인 transformer의 구성을 그대로 따랐으며 필요에 따라 수정하면 될 것으로 보입니다. 다만 학습 방식이 다릅니다. 위에서 기술하였던 Recency-based Sampling Strategy도 흥미로웠지만 본 논문의 방법 또한 상당히 흥미롭습니다.
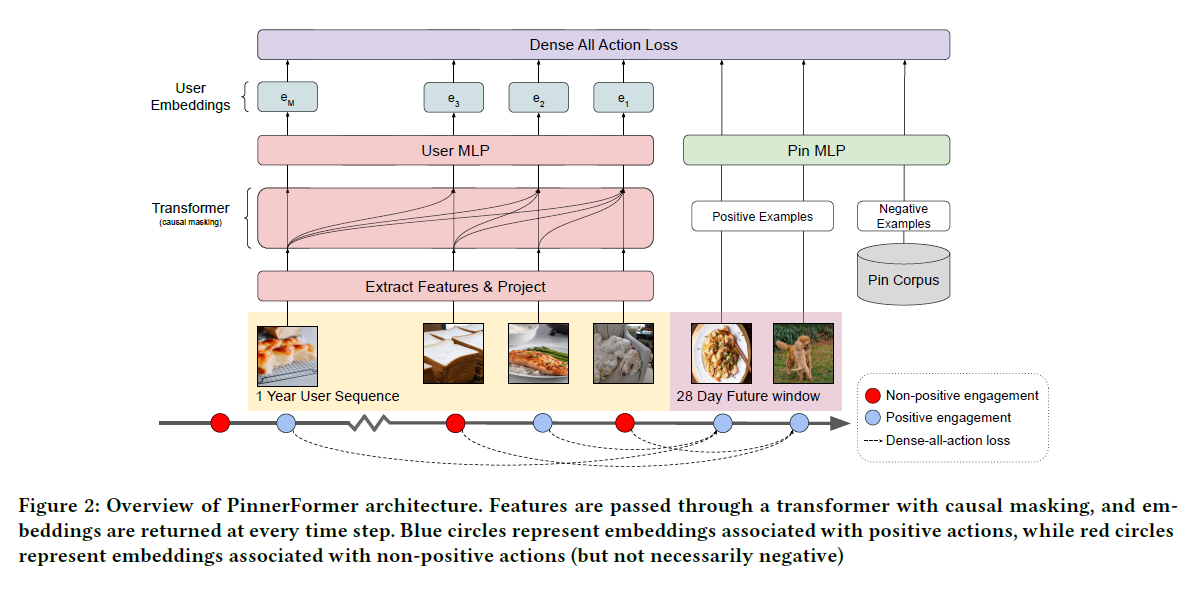

위 그림과 같이 학습 목표는 next 14-day window prediction 입니다. next-item prediction의 경우 근 미래 만을 예측하려는 경향을 보이는데, 본 논문과 같은 설정은 비교적 long-term preference를 학습할 수 있도록 유도하는 장치라고 생각할 수 있습니다. (dense all action loss)
그리고 가장 최근 시점의 final embedding 만을 사용하여 학습/추론하는 것이 아니라 sampling을 통해 모든 시점의 user embedding을 사용하여 학습하는 특징을 갖고 있습니다.
PinnerFormer의 Loss Function의 경우 sampled softmax with a logQ correction을 사용하였습니다. 이 함수는 negative item을 sampling 하는 데서 오는 bias를 일부 제거하는 효과를 갖고 있습니다. 논문에서는 negative sampling을 할 때 in-batch negative sampling과 random negative sampling을 혼합해서 사용하는 것을 고려하였다고 기술하고 있습니다.
최종적으로 User의 최근 action sequence를 추가적으로 반영하여 recency를 강화하였습니다.
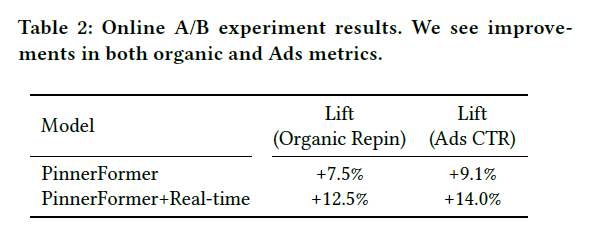
결과를 보면 기존 디자인이었던 PinnerSAGE의 성능을 능가하는 모습을 보여줍니다.
A Lightweight Transformer for Next-Item Product Recommendation
본 논문 역시도 Sequential Model을 활용한 추천 시스템에 대해 이야기하고 있습니다. 다만 모델 구조 보다는 분석 사례를 보여주고, recall과 nDCG와 같은 전통적인 평가 metric의 한계에 대해 살펴보고 있습니다.
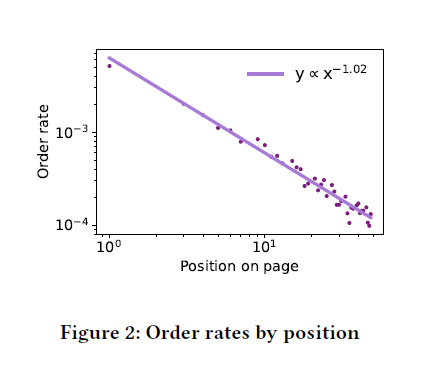
nDCG의 기본 discount factor는 $log_{2}$ 인데, 본 논문에서는 이 값이 실제로 적용하기에는 너무 작은 값이라고 이야기 합니다. 보통 nDCG를 그대로 사용하는 연구 자료가 대다수인 것을 감안하면 상당히 흥미로운 지적입니다. 위 그래프는 position에 따른 주문 비율의 관계를 나타낸 것인데, log-log plot을 보면 두 변수 사이의 관계는 $y \propto x^{1.02}$ 로 계산된다는 것을 알 수 있습니다. 이는 사실 wayfair의 데이터에서는 nDCG보다는 MRR이 더 적합한 metric이라는 것을 의미합니다. 개인적인 소견으로는 실제 진행하고 있는 project의 데이터를 보고 적합한 discount factor를 선정한다면 좀 더 유의미한 offline metric을 계산할 수 있지 않을까 생각해봅니다.