classic MAB 알고리즘들은 현실에서 적용하기 쉽지 않은 부분이 많습니다. 현실에서는 시간에 따라 environment의 특성이 변화하기 때문에 stationary environment를 가정하는 것은 적절하다고 보기 어렵습니다. 또한 데이터가 짧은 시간 안에 굉장히 많이 수집되거나 굳이 빠르게 업데이트를 할 이유가 없는 경우에는 모든 event에 대해 즉시 parameter를 update하지 않아도 되기도 합니다.
이러한 부분을 고려해서 실제 환경에서 MAB 알고리즘을 적용하기 위해 도움이 될 만한 paper들을 정리하고 응용 방안에 대해서도 생각해 보도록 하겠습니다.
Taming Non-stationary Bandits: A Bayesian Approach
non-stationary environment를 가정합니다. 논문에서 제안한 알고리즘은 dTS: Discounted Thompson Sampling 입니다. dTS의 목적은 과거 관측값의 영향력을 자동적으로 감소시키고 최근의 관측값들의 영향력을 상대적으로 크게 하여 시간이 지남에 따라 expected reward가 변화한다 하더라도 그에 대응하도록 하는 것입니다. 이 아이디어는 이전의 dynamic TS에서 먼저 제시된 바 있지만, 선택되지 않은 arm에 대한 parameter update가 이루어지지 않는다는 단점이 있었습니다. dTS에서는 이 부분을 보완했습니다.
dTS는 discount를 통해 과거 관측값의 영향력을 감소시키게 됩니다.

여기에서 $\gamma$ 가 discount factor의 역할을 하게 됩니다. 논문에서의 실험 환경에서는 0.8이 가장 우수한 성과를 보였지만 이는 튜닝을 통해 선정해야 할 것입니다. 위 과정에서 핵심은, 선택된 arm에 대해서는 reward를 고려한 update를 진행하고, 그렇지 않은 arm에 대해서는 discount만 진행한다는 것입니다.
여기서 잠깐 생각해야 할 것은, 이러한 update를 매 time step (t) 마다 해준다고 하면 arm이 굉장히 많다고 할 때 선택되지 않은 arm들의 경우 점점 과거 관측값의 영향력이 작아져서 학습이 잘 안될 가능성이 높다는 것입니다. 실제로 시뮬레이션을 해보면 베타 분포의 $\alpha, \beta$ 가 거의 제자리 걸음을 하면서 학습이 잘 안되는 경우를 확인할 수 있습니다. 이 때문에 경우에 따라서는 Batch Update 방식을 사용하거나 일정 주기 마다 discount를 하는 방식 등을 고려하는 것이 나을 것이라는 생각이 듭니다.
위 과정에서 중요한 것은, dTS는 선택되지 않은 arm의 prior distribution의 평균은 거의 그대로 유지하면서 분산은 증가시킨다는 것입니다. 이는 곧 시간이 지남에 따라 과거에 선택이 잘 되지 않았던 arm 들도 선택될 기회가 여전히 존재하도록 만들어 줍니다. 비록 평균 값은 작은 값이 된다 하더라도 분산이 크기 때문에 분포 자체가 낮고 긴 형태로 구성되기 때문에 낮은 확률이다 하더라도 높은 expected reward 값을 출력할 수 있는 것입니다.

논문에서는 dOTS를 간략하게 다룹니다. prior sample 값이 적어도 그 기댓값 보다는 크거나 같은 값을 출력하게 함으로써 exploitation의 영향을 더욱 강화합니다. 충분히 시도해볼 만한 세팅이라고 판단합니다.
논문 후반부의 실험 결과는 꽤 흥미롭습니다. 시뮬레이션을 위해 논문에서는 sinusoidal function을 사용하여 일정 주기를 갖는 reward 분포를 만들었습니다. 따라서 만약 밴딧 알고리즘이 시간이 흐름에 따라 변화하는 expected reward 분포를 포착하지 못한다면 regret은 일정 시간 후에 줄어들지 않고 늘어나게 될 것입니다.
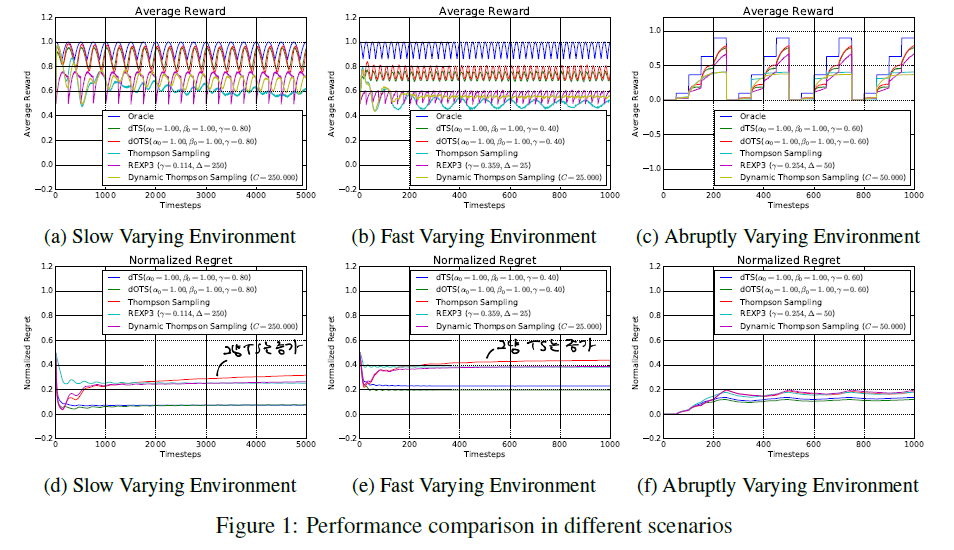
역시 traditional한 TS의 경우 stationary environment를 가정했기 때문에 regret이 후반부에 들어서 증가하는 모습을 보입니다.
dTS는 시간이 흐름에 따라 변화하는 expected reward를 반영할 수 있다는 큰 장점을 갖고 있습니다. 실제로 추천시스템을 만든다고 한다면 새로운 item이 계속 등장하는 상황에서 고정된 추천 리스트를 반환하는 것은 그리 좋은 방식이 아닐 것입니다. traditional TS의 경우 $\alpha, \beta$ 의 값이 계속 커짐에 따라 분포가 좁고 뾰족하게 변하면서 일정 시간 이후에는 더 이상 sampling한 결과가 잘 바뀌지 않는 현상을 보이는데, dTS는 이러한 부분을 보완해줄 수 있습니다. 다만 앞서 언급했듯이 업데이트 주기 등은 task에 맞게 설계해야 할 것으로 보입니다.
Learning Contextual Bandits in a Non-stationary Environment
역시 non-stationary enviroment를 가정합니다. dTS는 discount를 통해 변화에 대응했다면 이번 논문에서 제안하는 dLinUCB는 outdated 된 slave model(bandit)을 폐기하고 새로 추가하는 방식을 적용했습니다.
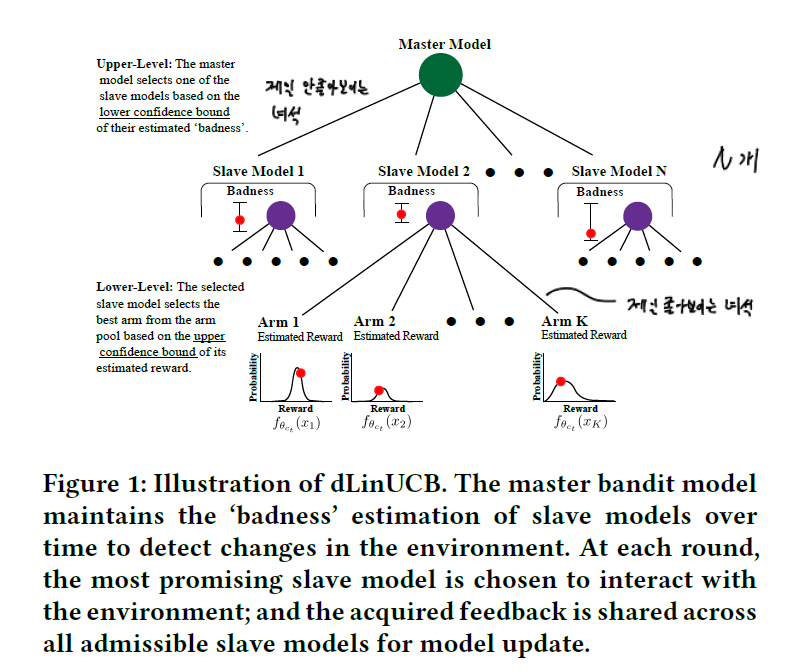
위 그림과 같이 모델은 계층적으로 구성되어 있습니다. lower level에서 slave bandit 들은 기본적인 MAB 역할을 수행합니다. upper level에서 master bandit은 slave bandit이 잘 하고 있는지 모니터링합니다. 그리고 어떠한 조건에 의해 slave bandit이 outdated 되었다고 판단하면 이를 폐기하고 새 bandit으로 교체해 줍니다.
본 논문에서는 예시를 위해 slave bandit을 LinUCB로 설계하였지만 그 어떠한 알고리즘도 기본 가정을 위배하지만 않는다면 사용할 수 있기 때문에 범용적으로 쓸 수 있는 구조로 보입니다.
다만 이론적인 설명이 다소 복잡해서 선뜻 구현하기 꺼려지는 reference라는 생각도 들긴 합니다.
A Batched Multi-Armed Bandit Approach to News Headline Testing
batch update를 고려한 논문입니다. 논문에서는 bTS를 구현하는 방법으로 2가지 방식을 제안합니다.

첫 번째는 summation update 방식입니다. 매우 간단하고 굳이 이 논문을 보지 않았더라고 생각할 수 있었던 방식일 것입니다. 구현하는 데에도 전혀 어려움이 없습니다. 단지 batch 내에서는 계사된 결과를 모아두었다가 batch 종료 시점에 update를 해주면 됩니다.

두 번째는 normalization update 방식입니다. 1개의 batch 동안 선택된 arm에 대해서 $S_k^t, F_k^t$ 를 업데이트한 후에 이를 normalize해서 $\alpha_k, \beta_k$ 를 업데이트하는 방식입니다. 위 수식에서 $M^t$ 는 batch 내의 event 수를 의미합니다.
논문에서는 summation 방식이 더욱 우수한 성과를 보여주었다고 기록하고 있습니다. 수행하는 task에 따라 결과는 달라질 수도 있겠지만 summation 방식이 더욱 간단하기 때문에 우선적으로 적용해보는 것이 좋지 않을까 생각해 봅니다.
엄청난 traffic을 감당해야 하거나, 굳이 엄청나게 빠른 속도로 update를 해도 되지 않는 상황이라면 bTS 의 개념을 적용해보는 것도 좋은 선택지가 될 것으로 보입니다.