이번 글에서는 multivariate time series 데이터에서 anomaly detection을 진행하는 방법 중 딥러닝 기반의 방법들에 대해 알아보겠습니다.
뛰어난 논문들이 많지만 아래 4개의 알고리즘에 대해 정리해 봅니다.
- MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks, 2019
- OmniAnomaly: Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network, 2019
- USAD: UnSupervised Anomaly Detection on multivariate time series, 2020
- GDN: Graph Neural Network-Based Anomaly Detection in Multivariate Time Series, 2021
시계열 데이터에서 이상 탐지를 위해 다양한 방법이 연구되었지만 과거의 많은 연구들은 univariate time series 데이터에 한정하는 경우가 많았습니다. 왜냐하면 dimension이 증가할 수록 classical한 방법들로는 그 사이의 interaction을 효과적으로 포착하기도 어려웠고, 개별적으로 modeling을 진행하기에는 리소스도 많이 들고 데이터의 손실 역시 컸기 때문입니다.
이러한 문제점을 해결하기 위한 방안으로 수년 전부터 딥러닝 기반의 알고리즘들이 제안되어 왔습니다.
MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks
anomaly detection을 수행해야 하는데, label 데이터가 부족하다면 비지도학습 방법을 고려할 수 있습니다. 본 논문에서는 변수 간 잠재 관계를 포착하고 reconstruction error와 discrimination error을 동시에 고려한 DR-score를 통해 이상치를 탐지하는 MAD-GAN이라는 알고리즘을 제시합니다.
본 알고리즘은 GAN에 기반합니다. generator와 discriminator에는 LSTM-RNN이 사용됩니다. generator는 random latent space을 input으로 하여 fake time series sequence를 생성하고 이를 disciminator에게 전달합니다. 그리고 discriminator는 생성된 fake data sequences와 real(normal) training data sequences를 구분하는 역할을 부여받습니다. multivariate time series는 discrimination 이전에 sliding window를 활용하여 복수의 sub-sequences로 나눠집니다.
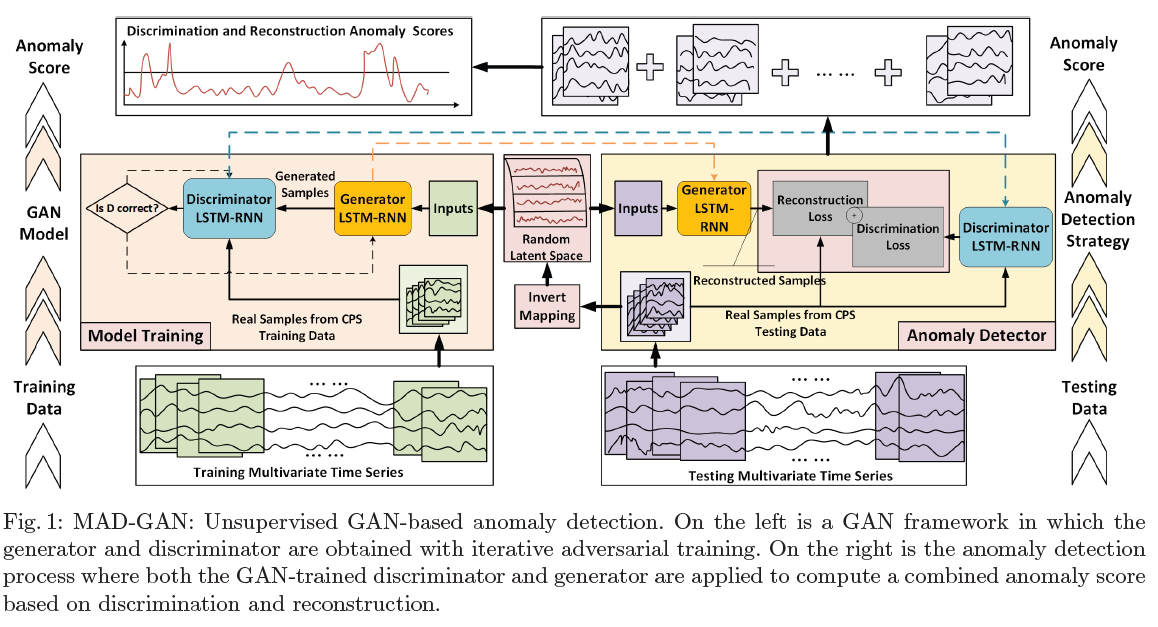
$T$ 개의 변수(stream)가 존재한다고 할 때 dataset $\mathcal{X}$ 를 training, test dataset으로 나눈다고 하면 $\mathcal{X}^{train} \subseteq R^{M, T}, \mathcal{X}^{test} \subseteq R^{N, T}$ 로 표기할 수 있습니다. 모든 학습 데이터는 정상이라고 가정합니다.
효과적인 학습을 위해서 sliding window를 적용하여 복수의 sub-sequences를 만들고, 같은 방식으로 random space에서 추출한 multivariate sub-sequences $Z$ 또한 생성합니다.
\[X = \{ x_i, i = 1 \sim m \} \subseteq R^{s_w, T}, m = \frac{M - s_w}{s_s}\] \[Z = \{ z_i, i = 1 \sim m \}\]$s_w$ 는 window size, $s_s$ 는 step size를 의미합니다.
training objective는 아래와 같습니다.
\[\text{min}_G \text{max}_D V (D, G) = \mathcal{E}_{x \sim p_{data} (X)} [logD(X)] + \mathcal{E}_{z \sim p_{z} (Z)} [log(1-D(G(z)))]\]충분히 학습을 한 이후에 학습된 $D_{rnn}$ 과 $G_{rnn}$ 은 $\mathcal{X}^{test}$ 에 존재하는 이상치를 탐지하기 위해 사용될 수 있습니다. 이를 위해서 본 논문에서는 DR-score를 계산할 것을 제안합니다. 기본적으로 본 논문에서 제시하는 GAN-based 이상치 탐지는 아래와 같이 2가지 부분으로 구성됩니다.
-
discrimination-based anomaly detection
학습된 discriminator는 fake data(anomaly)와 real data를 구분할 수 있습니다. 따라서 $D$ 를 이상치 탐지를 위한 직접적인 도구로 활용합니다. -
reconstruction-based anomaly detection
학습된 generator는 realistic sample을 생성할 능력을 갖추었습니다. 따라서 normal data의 분포를 반영하는 모델이라고 볼 수 있습니다. 따라서 $G$ 는 $X^{test}$ 와 $G(Z^k)$ 와의 유사도를 계산하는 역할을 수행합니다. 즉 autoencoder로 이상치 탐지를 수행할 때 reconstruction error를 줄이는 것과 유사한 작업을 진행하는 것입니다.
최적의 $Z^k$ 를 찾기 위해서는 아래와 같은 objective가 필요할 것입니다. 이 때 유사도는 간단하게 covariance로 정의합니다.
\[\text{min}_{Z^k} Error(X^{test}, G_{rnn}(Z^k)) = 1 - Similarity(X^{test}, G_{rnn}(Z^k))\]위 objective에 기반하여 충분한 iteration이 진행되었다면 이제 anomaly detection loss를 다음과 같이 세울 수 있습니다.
\[L_t^{test} = \lambda \Sigma_{i=1}^n \vert x_t^{test, i} - G_{rnn} (Z_t^{k, i}) \vert + (1 - \lambda) D_{rnn} (X_t^{test})\]$n$ 개의 변수와 $s_w$ 개의 sub-sequences에 대하여 anomaly detection loss들을 구할 수 있을 것입니다. 이제 이렇게 구한 loss를 original time series에 다시 매핑하는 작업을 통해 DR-score를 구합니다.
이제 이 DR-score를 활용하여 anomaly score를 구하면 됩니다.


자세한 설정 정보와 실험에 대해서는 논문 본문을 참고하시길 바랍니다.
OmniAnomaly: Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network
OmniAnomaly는 stochastic rnn을 이용하여 robust한 이상 탐지를 수행하는 알고리즘입니다. 본 논문에서는 label의 부족으로 비지도학습의 관점을 채택했다고 밝히고 있으며, temporal dependence와 stochasticity를 모두 고려하여 multivariate time series 데이터의 normal 패턴을 포착한다고 이야기하고 있습니다.
sequence 길이는 $N$ 이고 변수의 개수는 $M$ 개 입니다. $\mathbf{x}_{t - T:t} \in (M, T+1) $ 는 multivariate sequence obervations 입니다.
전체 구조는 아래와 같습니다. 데이터 전처리 및 정규화 과정을 거친 뒤에는 sliding window 과정을 통해 여러 sequence로 데이터를 분리 생성합니다.
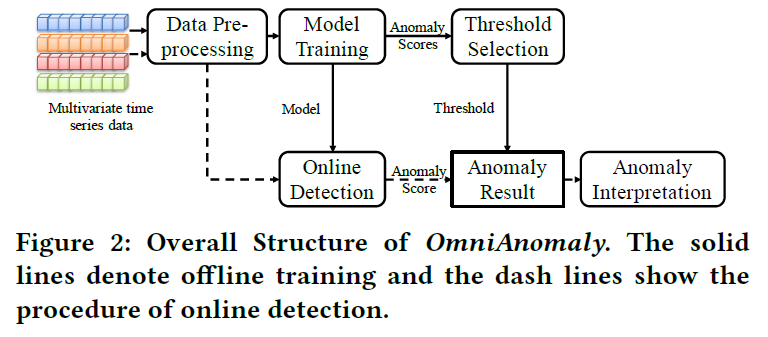
본 모델에서는 GRU를 이용하여 시계열 데이터에서의 temporal dependence를 포착합니다.
그리고 VAE를 이용하여 관측값을 stochasitc space에 매핑합니다.
그런데 이 때 VAE의 구성 요소인 qnet에서 아래 식은 종종 diagonal gaussian이라고 가정합니다.
본 논문에서는 non-gaussian posterior density인 위 식을 학습하기 위해 invertiable mapping을 이용하는 planar NF라는 기법을 제안합니다.
일단 $q_{\phi} (\mathbf{z}_t \vert \mathbf{x}_t) $ 에서 $z_t^0 $ 을 추출합니다. 그리고 연속적인 invertible mapping를 통해 $\mathbf{z}_t^K = f^K (f^{K-1} (…f^1(z_t^0))) $ 을 얻습니다. 이 때 $f^k$ 는 invertible mapping 함수이며 학습 가능한 파라미터를 가진 non-linear layer에 해당합니다. (상세 식은 논문 참고)
qnet에서 이렇게 planar NF에서 얻은 최종 결과물 $\mathbf{z}_t^K$ 를 stochastic variable $\mathbf{z}$ 로 사용합니다. 이를 통해 input 데이터가 복잡한 분포를 갖고 있다 하더라도 좀 더 robust한 representation을 학습할 수 있도록 합니다.
그리고 잠재 공간에 존재하는 stochastic variable 사이의 temporal dependence를 명시적으로 모델링하기 위해 Linear Gaussian State Space Model이라는 stochasitc variable connection이라는 방법이 제안됩니다. 이 장치는 stochastic variable과 GRU hidden variable를 연결해줍니다.
전체적으로 모델은 다음과 같이 encode - decode의 구조를 갖게 됩니다.
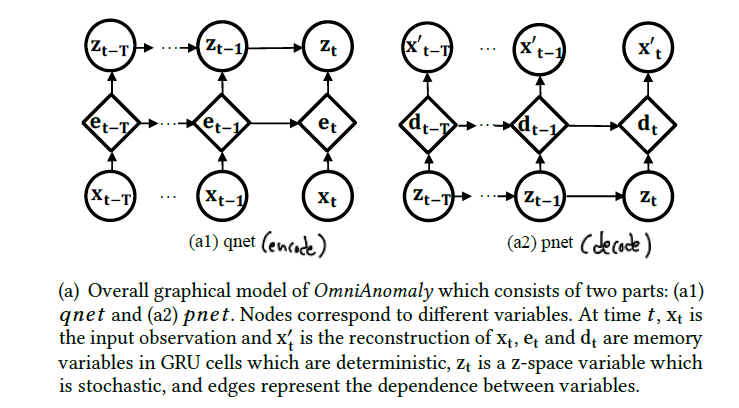
reconstruction loss를 설정하여 normal data에 대한 정확한 representation을 얻게 됩니다.
qnet은 아래와 같은 구조를 갖고 있습니다.
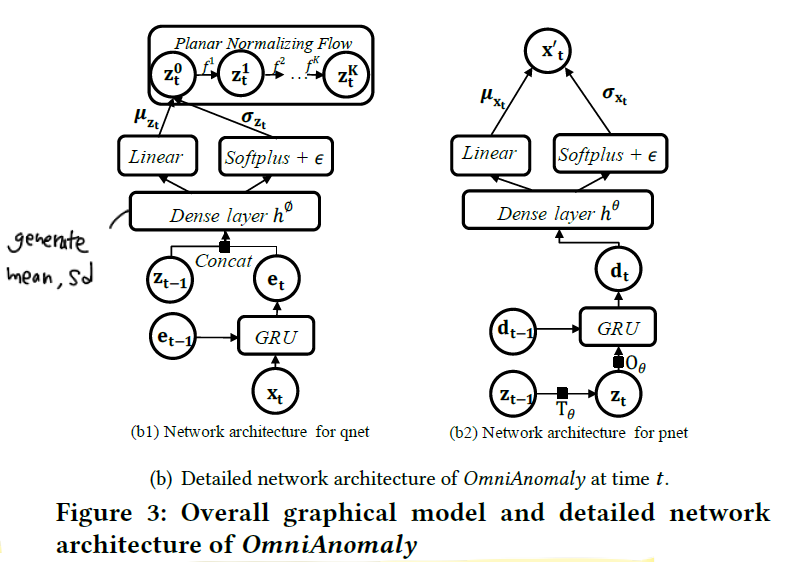
자세한 과정은 논문 본문을 참고하길 바랍니다. 바로 위에서 설명하였듯이 결국 위 구조를 통해 deterministic한 GRU hidden variable과 stochastic variable 사이의 연결을 생성하여 더욱 robust한 representation을 얻게 되는 것입니다.
최종적으로 reconstructed data는 아래 분포에서 추출됩니다.
\[\mathbf{x}_t^{'} \sim \mathcal{N}(\mathbf{\mu}_{\mathbf{x}_t} \mathbf{\sigma}^2_{\mathbf{x}_t} \mathbf{I})\]그리고 아래 벡터로 부터 생성됩니다.
\[\mathbf{x}_t^{'} \leftarrow \mathbf{z}_t\]만약 $t$ 시점에서 reconstructed data가 original data $\mathbf{x}_t$ 와 많이 다르다면 이를 이상치라고 판별할 수 있을 것입니다.
추가적으로 논문 후반부에선 오프라인 상황에서 모델을 어떻게 학습하는지, threshold는 어떻게 자동적으로 선택하는지, 이상치 해석은 어떻게 하는지에 대해서도 다루고 있으니 본문을 참고하시길 바랍니다.
USAD: UnSupervised Anomaly Detection on multivariate time series
USAD는 구조적인 측면에서는 autoencoder에 기반하고, 학습 방법 측면은 GAN의 adversarial training 기법을 응용해서 사용합니다. autoencoder로 anomaly detection을 할 때 가장 크게 문제가 되는 것 중 하나가, reconstruction 자체를 너무 잘해버려서 이상치 조차도 정상 값처럼 복원이 되어버린다는 것인데 본 논문에서는 이를 구조적으로 보완하여 극복하는 방법에 대해 기술하고 있습니다.
비지도학습이므로, training input은 모두 normal이라고 가정합니다. 본 논문에서는 window 길이 $K$ 에 대해 다음과 같이 sequence input을 정의합니다.
\[W_t = (\mathbf{x}_{t-K+1}, ..., \mathbf{x}_{t-1}, \mathbf{x}_t)\]간단하게 표기하기 위해 $W$ 를 training input window, $\hat{W}$ 를 unseen input으로 표기합니다.
autoencoder로 anomaly detection을 한다면 기본적으로 다음과 같은 training objective를 설정하게 됩니다.
\[L_{AE} = \Vert X - AE(X) \Vert_2\] \[AE(X) = D(Z), Z = E(X)\]USAD는 위 식을 참고하여 two-phase adversarial training framework를 제시합니다. 이 방식을 통해 autoencoder의 과한 reconstruction 문제와 GAN의 높은 학습 난이도라는 문제를 해결하였다고 합니다.
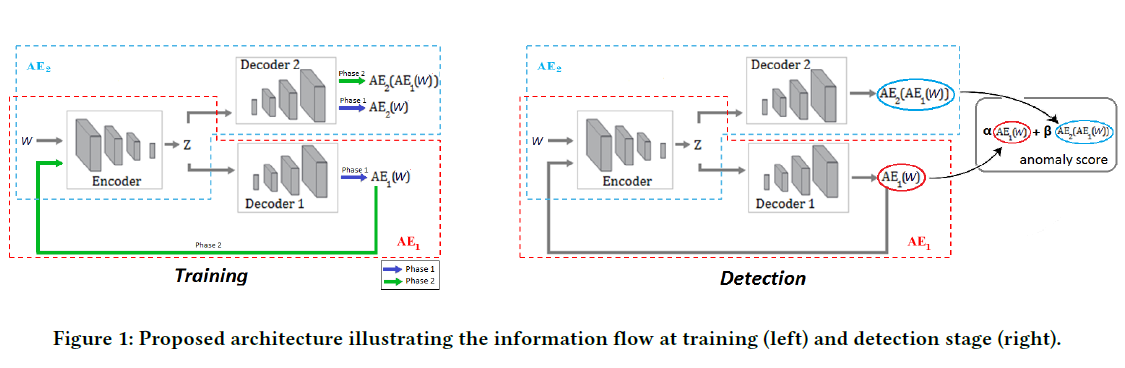
USAD는 총 3개의 요소로 구성됩니다. 2개의 decoder는 같은 encoder 구조를 공유합니다.
- encoder network $E$
- 2 decoder networks $D_1, D_2$
2단계로 이루어진 학습 과정에 대해 살펴보겠습니다. 먼저 autoencoder trainining 입니다. 일단 2개의 autoencoder가 input을 복원하도록 학습시킵니다. training objective는 다음과 같습니다.
\[L_{AE_1} = \Vert W - AE_1(W) \Vert_2\] \[L_{AE_2} = \Vert W - AE_2(W) \Vert_2\]다음으로 $AE_2$ 는 $AE_1$ 로부터 온 데이터가 실제 데이터인지 복원된 데이터인지 구분하도록 학습합니다.. 반면 $AE_1$ 는 $AE_2$ 를 속이는 generator 역할을 수행합니다. $AE_1$ 로부터 온 데이터는 $E$ 에서 $Z$ 로 거치는 동안 압축되고 다시 $AE_2$ 로부터 복원됩니다.
즉 $AE_1$ 의 목적은 $W$ 와 $AE_2$ 의 output의 차이를 줄이는 것이고, $AE_2$ 의 목적은 이 차이를 더욱 크게 만드는 것입니다. training objective는 다음과 같습니다.
\[min_{AE_1} max_{AE_2} \Vert W - AE_2 (AE_1 (W)) \Vert_2\]이제 위에서 기술한 2개의 training objective를 하나로 합칠 차례입니다.
\[L_{AE_1} = \frac{1}{n} \Vert W - AE_1(W) \Vert_2 + (1 - \frac{1}{n} \Vert W - AE_2(AE_1(W))) \Vert_2\] \[L_{AE_2} = \frac{1}{n} \Vert W - AE_2(W) \Vert_2 + (1 - \frac{1}{n} \Vert W - AE_2(AE_1(W))) \Vert_2\]$n$ 은 training epoch을 의미합니다.
inference 과정은 조금 난해합니다. anomaly score는 아래와 같이 구합니다.
\[score = \alpha \Vert \hat{W} - AE_1(\hat{W}) \Vert_2 + \beta \Vert \hat{W} - AE_2 (AE_1(\hat{W})) \Vert_2\]$\alpha + \beta = 1$ 이며, 이는 false positive와 true positive 사이의 trade-off를 조절하는 역할을 수행하게 됩니다. 만약 $\alpha$ 가 더 큰 값을 갖게 된다면, true positive의 수를 줄이면서 또한 false positive의 수를 줄일 수 있게 됩니다. 이는 더욱더 복원력이 강해져서 정상이 아닌 것을 정상이라고 할 확률과 이상치를 정상이라고 판단할 확률 모두를 낮추기 때문입니다.
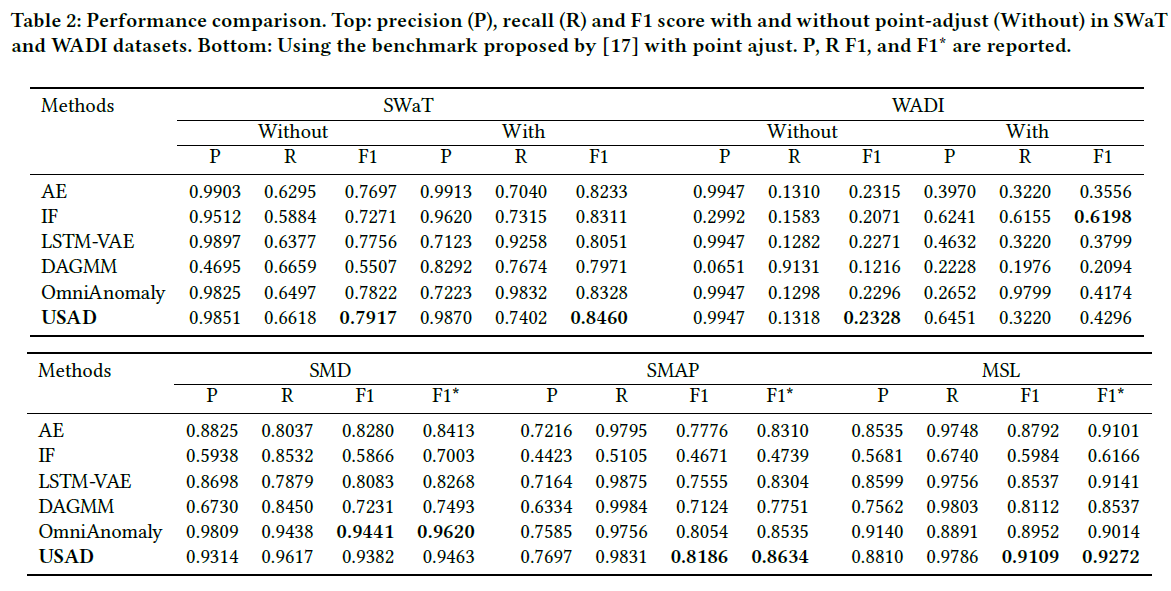
알고리즘 구조 그림과 학습 pseudo code 및 experiment 결과를 첨부하며 마무리합니다.


GDN: Graph Neural Network-Based Anomaly Detection in Multivariate Time Series
고차원의 데이터셋, 즉 다변량 데이터에서 변수(sensor) 사이의 interaction을 잘 포착하는 것이 multivariate time series forecasting의 핵심 요소입니다. classical auto-regressive model 모델의 경우 복잡한 비선형 특성을 모델링하기에 적합하지 않습니다. CNN, LSTM, GAN 등의 구조에 기반한 딥러닝 방법론 역시 등장했지만 본 논문에서는 이 역시 변수 간 관계를 명확히 학습하기에는 부족하다고 이야기합니다. 그리고 대안으로 GNN을 접목한 방법론을 제시합니다. GNN에 대한 기반 지식이 부족하다면 이 곳에 있는 몇 가지 글을 읽어보셔도 좋을 것 같습니다.
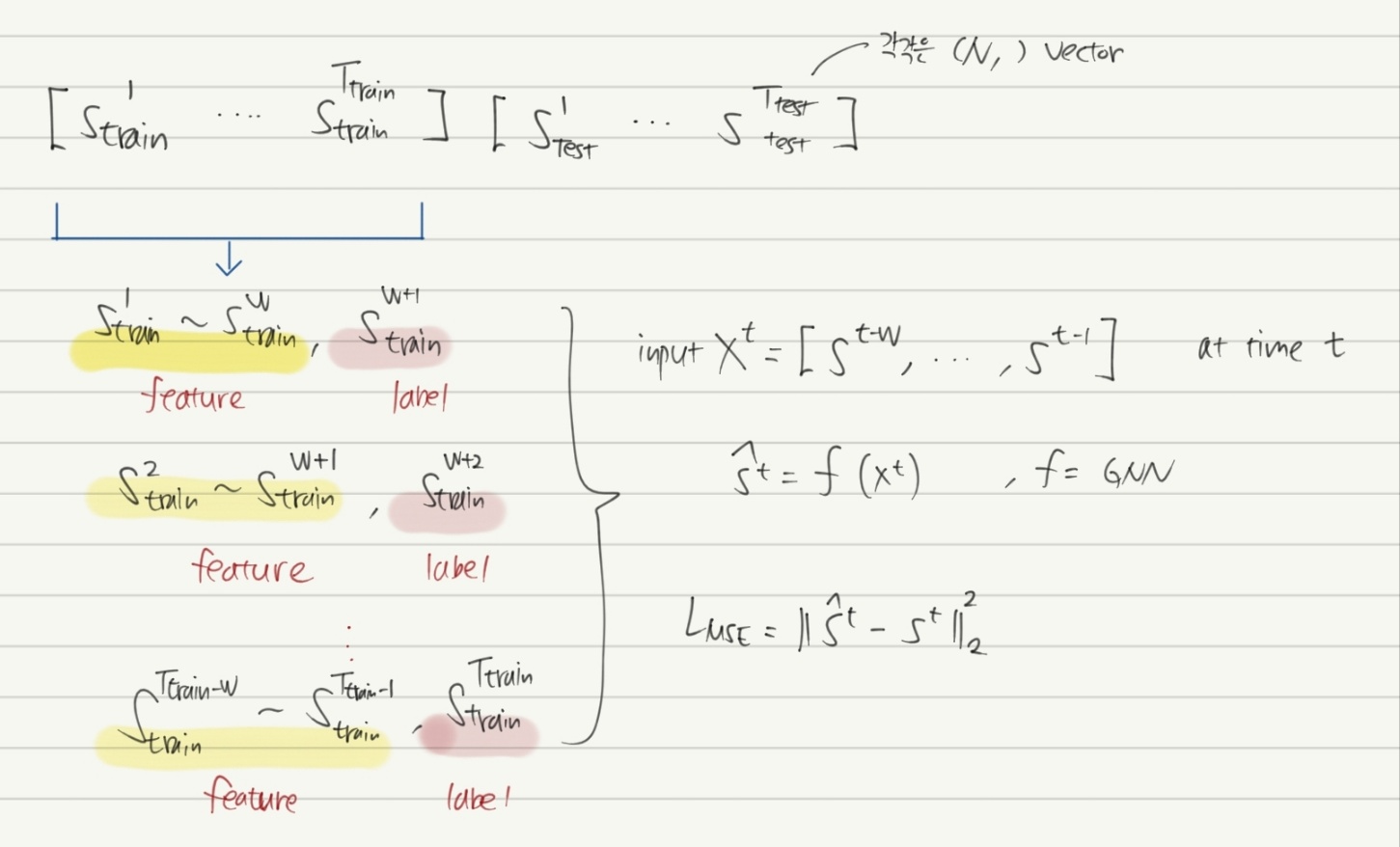
데이터 형상은 위와 같습니다. 기본적으로 본 논문에서 제시하는 방법은 prediction error를 최소화하는 방법입니다. $w$ 크기의 window size를 설정하고 이를 sliding 하면서 학습/테스트 데이터를 생성합니다. 결과적으로 $N$ 개의 sensor에 기반하여 $t$ 시점의 모델은 binary classification을 수행하게 됩니다. (이상치 여부를 0 또는 1로 나타냄)
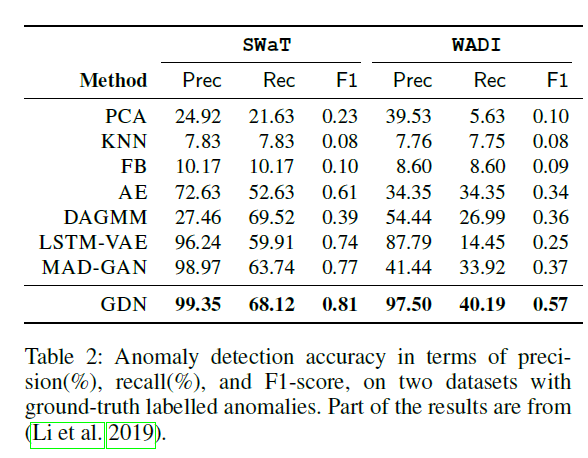
참고로 논문에서 사용한 SWaT, WADI 데이터셋의 경우 이상치 비율이 각각 11.97%, 5.99% 인데 실제 데이터에서는 이보다 이상치 비율이 현저히 적은 경우가 많을 것이라고 예상됩니다. 따라서 label로 설정할 수 있는 이상치 데이터가 충분한 경우에만 GDN을 그대로 이용할 수 있을 것입니다.
GDN은 다음과 같이 구성되어 있습니다.
- sensor embedding
- graph structure learning
- graph attention-based forecasting
- graph deviation scoring
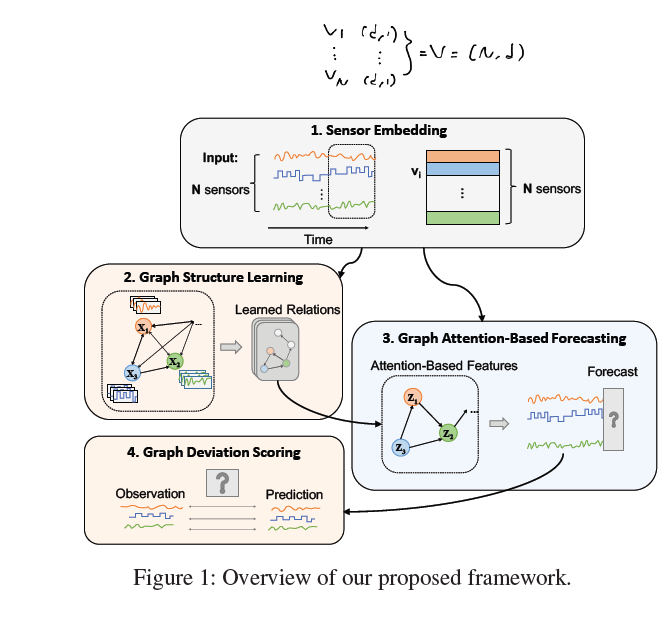
여러 단계로 나와있습니다만 input 데이터에 있는 $N$ 개의 sensor의 시계열 데이터를 각각 임베딩 벡터로 나타내고 이를 directed graph network의 node feature로 사용합니다. 그리고 $N$ 개의 모든 sensor에 대해 graph attention 구조로 message passing & aggregation을 수행합니다. 그렇게 되면 총 $N$ 개의 벡터가 결과물로 산출될 것입니다.
이들은 다시 graph attention을 적용하기 이전의 벡터와 element-wise 곱을 수행한 뒤 fully-connected layer를 통과하여 $N$ 의 길이를 갖는 vector output으로 출력됩니다. 그리고 이 예측값으로 binary classification을 수행하는 것입니다.
\[\hat{s}^t = f_{\theta} ([\mathbb{v}_1 * \mathbb{z}_1^t, ..., \mathbb{v}_N * \mathbb{z}_N^t])\]구조는 매우 직관적입니다. time series data를 하나의 embedding vector로 표현하고, 이 vector 사이의 interaction을 포착하기 위해 graph attention network를 이용합니다. 그리고 이들을 모두 모아 하나의 layer를 통과시켜 최종 예측 값을 얻습니다.
이제 실제 상황에서 어떻게 이상치를 판별할지 알아봅시다. 논문에서는 이 과정을 graph deviation scoring이라고 명명하고 있습니다.
sensor $i$ 의 time $t$ 에서의 에러 값은 아래와 같이 정의할 수 있습니다.
\[Err_i(t) = \vert s_i^t - \hat{s}_i^t \vert\]각 sensor의 특징은 제각각이므로 그들의 deviation은 서로 다른 scale을 갖고 있을 수 있습니다. 즉 정규화가 되어 있지 않은 상황이므로 다음과 같이 anomalousness score에 robust normalization을 적용해 줍니다.
이 때 $\tilde{\sigma}_i$ 는 median을, $\tilde{\mu}_i$ 는 IQR의 제곱을 의미합니다. 이렇게 $N$ 개의 sensor에 대해 모두 anomalousness score를 얻은 후 max 함수를 통해 대표값을 산정합니다.
\[A(t) = \text{max}_t a_i (t)\]결과값의 갑작스러운 변화를 완화하기 위해서 SMA: simple moving average 기법을 적용하여 최종적으로 smooted score $A_s (t)$ 를 구합니다. 그리고 이 score가 특정 임계값을 넘으면 이상치라고 판별하게 됩니다. 이 때 threshold를 정하는 방법은 굉장히 다양한데, 본 논문에서는 이를 정하는 데에 있어 hyper-parameter를 남겨두고 싶지 않았기 때문에 validation data를 이용해서 threshold를 정했다고 서술하고 있습니다.
실험 결과를 살펴보면, PCA, KNN과 같은 classic한 알고리즘부터 AE, DAGMM, LSTM-VAE, MAD-GAN 등 수 년 사이에 등장한 딥러닝 알고리즘들과도 비교하고 있습니다. 보통의 논문과 마찬가지로 precision, recall, f1-score을 이용하여 평가를 진행하였습니다.